Povestea cercetătoarei române briliante de care se tem hackerii și giganții tech. Americanii au inclus-o în topul celor mai străluciți savanți
Născută în Ploiești, formată la Politehnica din București și ajunsă din 2011 profesoară la Columbia University, Roxana Geambașu e una dintre cele mai respectate voci în securitatea datelor și arhitectura confidențialității. Lucrează cu Google și Meta, iar proiectele ei au fost adoptate de giganții tech și influențează modul în care miliarde de oameni sunt protejați online. Nu întâmplător, americanii au inclus-o în topul primilor 10 savanți în 2014.

Roxana Geambașu în campusul Universității Columbia. FOTOGRAFII: Arhivă personală R. G.
Într-un interviu pentru „Adevărul“, Roxana Geambașu vorbește despre cum a trecut de la olimpiadele de Matematică din România la doctorat în SUA, despre proiectul Vanish – sistemul de date autodistructive care a atras atenția lumii întregi, despre ce a descoperit monitorizând felul în care Google folosea e-mailurile utilizatorilor pentru publicitate și despre faptul că, în 2026, cel mai mare risc pe internet nu este supravegherea, ci dezinformarea amplificată de AI. Românca povestește și despre viața dincolo de carieră: alergatul prin parcurile din Manhattan ca pe niște autostrăzi și buncărul de cărți ascuns sub Bryant Park, lucruri care îi amintesc, după ore întregi de coduri și cercetare, că lumea funcționează pe mai multe niveluri decât se vede la suprafață.
Adevărul: Sunteți printre cele mai apreciate voci în securitatea datelor și arhitectura confidențialității, iar americanii v-au inclus în topul savanților geniali. Cum a fost parcursul dumneavoastră academic și când ați descoperit pasiunea pentru științele exacte?
Roxana Geambașu: În școală mi-au plăcut foarte mult matematica, biologia, limbile străine – mai ales engleza – și informatica. La materiile astea au contat enorm profesorii. În generală am avut o profesoară de matematică, doamna Cârnici, foarte bună – dură, dar clară și inspirantă. Învățam și pentru că îmi plăcea de ea: era sigură pe ea, foarte inteligentă, și îmi doream să fiu și eu așa. Apoi au venit și primele rezultate la olimpiade, care m-au motivat și mai mult. În liceu am fost la clasă de informatică, deci făceam multă programare. Îmi plăcea și eram bună, dar la matematică simțeam că venea mai natural. Am avut și în liceu un profesor de matematică foarte bun, domnul Apostolescu, care m-a pregătit și m-a susținut mult. Biologia mi se părea fascinantă – aveam senzația că descopăr mereu ceva nou –, iar pentru limbile străine am avut mereu o înclinație.
Roxana Geambașu la o vârstăn fragedă
Când a început să se contureze dorința de a merge la Politehnică?
Decizia pentru Politehnică nu a fost deloc clară de la început. M-am hotărât abia pe la mijlocul clasei a XII-a. Părinții mei făcuseră și ei Politehnica, iar fratele meu era deja la Calculatoare, deci probabil că m-au influențat. Dar eu oscilam: mă pregăteam și pentru ASE (Cibernetică), mă gândeam la Matematică la Universitate, iar până prin clasa a XI-a luasem în calcul și Medicina, pentru că îmi plăcea biologia. Sincer, la vârsta aceea nu înțelegeam foarte bine diferențele dintre inginerie, matematică pură sau informatică aplicată în economie. Medicina era clar altceva, dar nu cred că mă vedeam cu adevărat cu bisturiul în mână. În final, cred că decizia a fost mai degrabă pragmatică decât profund vocațională: Politehnica accepta fără concurs elevii care obținuseră premii la olimpiadele naționale, iar eu luasem premiul III la matematică în clasa a XI-a. Universitatea și ASE nu ofereau această variantă. A fost o alegere care s-a dovedit foarte potrivită, pentru că apoi am început să înțeleg tot mai bine domeniul și să dezvolt o pasiune reală pentru ingineria calculatoarelor. Cred că povestea asta arată două lucruri: cât de mult pot influența profesorii parcursul unui copil și faptul că alegerile importante nu sunt întotdeauna rezultatul unor calcule foarte sofisticate – uneori sunt mai simple și mai arbitrare decât ne imaginăm.

De la „Leu“ la Washington
Ați fost șefă de promoție la Politehnica din București în 2005. Privind în urmă, ce ați învățat la Politehnică și v-a fost cel mai util mai târziu în cariera din SUA?
Cred că cel mai important lucru pe care l-am învățat în facultate a fost munca susținută. Politehnica mi-a oferit, desigur, o bază solidă de concepte și multă încredere că pot rezolva probleme complexe și pot construi sisteme serioase. Dar, dincolo de teorie, m-a învățat să muncesc mult și constant. Îmi amintesc mai ales cursurile de sisteme de operare, foarte intense, cu multe teme. Făceam nu doar cerințele obligatorii, ci și părțile opționale. De exemplu, era obligatoriu să modificăm diverse componente în Linux, iar varianta pentru Windows era opțională – eu le făceam pe amândouă. Era fascinant să văd diferențele. Nu știu exact de ce făceam mereu „mai mult“, probabil era un amestec de interes, dorința de a lua note bune și satisfacția că învăț lucruri pe care nu le știe toată lumea. M-a motivat mereu ideea de a avea niște abilități speciale, câștigate prin efort. Când am ajuns la University of Washington pentru doctorat, eram deja obișnuită să construiesc lucruri și să nu mă sperii de complexitate. La început, în întâlniri, aproape că nu vorbeam – nu eram obișnuită nici cu limba, nici cu stilul lor foarte liber de brainstorming. După câteva săptămâni în care i-am ascultat, m-am apucat pur și simplu să implementez în cod ce discutau ei. La următoarea întâlnire, le-am făcut un demo. Am aflat mai târziu că i-a impresionat mult și că atunci au decis să investească serios în mine. Din acel moment am început să lucrăm foarte strâns. Cred că acei ani de muncă intensă la Politehnică – și obiceiul de a face lucrurile temeinic, fără ocolișuri sau trișare – au avut un impact enorm asupra parcursului meu și asupra oportunităților pe care le-am avut ulterior.

Roxana Geambașu la Seattle (2005)
De ce ați ales University of Washington pentru doctorat?
Când m-am hotărât să merg în SUA pentru doctorat, am trimis aplicații la mai multe universități și am fost acceptată la câteva. Am avut apoi telefoane de recrutare cu echipele de acolo. De fiecare dată mă întrebau ce vreau să fac și unde mai am oferte. Eu spuneam că mă interesează sistemele distribuite și că am fost admisă și la University of Washington. Reacția aproape unanimă era: „Ah, grupul de sisteme distribuite de la Washington e foarte puternic“. Eu mi-am zis că oamenii ăștia știu ei ce știu, așa că am ales University of Washington.
Cum a fost adaptarea la sistemul academic american?
Adaptarea a fost intensă la început, dar surprinzător de naturală după primele săptămâni. În primele întâlniri eram foarte timidă, nu scoteam un cuvânt. Ritmul discuțiilor era rapid, ideile circulau liber, iar eu simțeam că nu țin pasul. Engleza o știam bine în scris – îmi scrisesem chiar și lucrarea de diplomă în engleză –, dar nu o exersasem deloc verbal. În România eram obișnuită mai mult cu ascultatul cursului și luatul de notițe, nu cu dezbateri, brainstorming sau contrazicerea profesorilor. Așa că, la început, am stat mai mult și am ascultat. Încet, încet mi-am găsit vocea, mai ales după ce am văzut că ideile și munca mea sunt apreciate.

Diferențele dintre educația americană și cea din România
Care vi se par cele mai mari diferențe dintre sistemul academic din România și cel din SUA?
Cred că una dintre marile diferențe dintre sistemele academice este tocmai această cultură a dezbaterii și a inițiativei. În SUA ești încurajat să îți spui opinia, chiar dacă nu e perfect formulată sau nu esti sigur că e corectă, și să construiești idei împreună cu ceilalți. Asta mi-a schimbat mult modul de a lucra și de a gândi.
Ați lucrat cu nume mari din domeniu, precum Hank Levy şi Steve Gribble. Cum v-au influențat acești mentori felul în care faceți cercetare?
Am avut trei coordonatori principali: Hank Levy, Steve Gribble și Yoshi Kohno. Hank și Steve veneau din zona sistemelor, iar Yoshi din securitate. Am învățat enorm de la ei și, sincer, le datorez în mare parte felul în care gândesc astăzi cercetarea. M-au învățat ce înseamnă rigoarea: o idee, oricât de frumoasă, valorează zero dacă nu o validezi temeinic. Partea grea nu este să ai o ipoteză, ci să o testezi serios, să o împingi până la limită, să vezi unde crapă. Acolo e, de fapt, munca adevărată. În același timp, m-au învățat să nu-mi fie teamă de idei ambițioase și să nu mă descurajez la primul „nu se poate, pentru că...“. Sau la următoarele 50. Dacă o idee chiar merită urmărită, aproape sigur vor exista multe motive pentru care pare imposibilă. Dacă nu ar fi obstacolele, probabil ar fi realizat-o deja altcineva. Nu le ignori, ci le iei pe rând și le ataci sistematic. Desigur, trebuie să știi și când să te oprești. Există un echilibru fin între perseverență și încăpățânare oarbă, pe care îl înveți în timp, iar coordonatorii mei mi-au oferit și exemple de proiecte pe care le-au închis, recunoscând că nu au mers. Poate cea mai importantă lecție a fost că, în cercetare, încerci să faci lucruri pe care nimeni nu știe să le facă. Iar ca să reziști acolo, trebuie să lucrezi la probleme care chiar „te dor“, care te enervează, lucruri care ți se par profund greșite. Doar acelea îți dau energia să mergi mai departe când lucrurile nu ies.
„A fost o lecție importantă despre diferența dintre a face cercetare și a o preda“
Cum a fost tranziția de la doctorand la profesor la o universitate din Ivy League?
A fost foarte bruscă (zâmbește). Mi-am depus teza pe la mijlocul lui august la University of Washington, iar la început de septembrie predam deja primul curs la Columbia. Nici nu aveam încă diploma oficială când am intrat la clasă – am fost numită temporar „instructor“ până au sosit actele și am devenit oficial profesor asistent. Schimbarea a fost uriașă. Am trecut de la un laborator plin de colegi, unde discutam continuu idei și ne ajutam unii pe alții, la un birou gol și la responsabilitatea de a preda și de a coordona propriii mei studenți. Doctoratul te pregătește foarte bine pentru cercetare, dar mult mai puțin pentru predare și mentorat – iar ca profesor trebuie să le faci pe toate trei.

Cum ați văzut, ca profesor, noua generație de studenți?
La clasă am avut un mic șoc când mi-am dat seama că studenții nu făceau clar diferența între concepte bine stabilite și idei noi, încă în dezbatere. Eu vorbisem până atunci doar cu cercetători, pentru care această distincție e implicită. În cercetare există un fel de „test al timpului“: ideile noi sunt privite cu reținere până sunt validate. Studenților însă nu le era clar unde se termină manualul și unde începe frontiera. Când am realizat confuzia, am luat-o de la capăt și am explicat ce e consolidat și ce e încă discutabil. Studenții au fost foarte înțelegători și chiar m-au încurajat să continui; și-au dat seama că stăpâneam tehnologiile, doar că încă învățam cum să le predau. A fost o lecție importantă despre diferența dintre a face cercetare și a o preda. La cercetare mă simțeam în largul meu. În primul semestru lucram la un sistem de securizare a datelor pe Android și „hackuiam“ liniștită, ca în doctorat. În al doilea semestru au venit primii mei studenți. Credeam că sunt pregătită, dar am simțit pentru prima dată greutatea responsabilității: nu mai era vorba doar despre munca mea, ci și despre viitorul lor. Țin minte un articol la care am lucrat atunci și la care am plâns din cauza presiunii – nu eram sigură că îl vom termina la timp sau că va fi acceptat, iar decizia de când și cum trimitem articolul era a mea. Ca doctorand, responsabilitatea finală era a coordonatorilor, acum era a mea. Cu timpul înveți să gestionezi presiunea și incertitudinea, dar începutul a fost intens. A fost o tranziție abruptă, dar care m-a făcut să cresc foarte repede.
Bătălia pentru datele personale
În doctorat ați studiat cum își pot recăpăta utilizatorii controlul asupra datelor lor. Care era problema pe care încercați să o rezolvați?
Perioada în care mi-am făcut doctoratul, a doua jumătate a anilor 2000, a fost un moment de schimbare tehnologică semnificativă. Webul se stabilizase, explodau rețelele sociale si aplicațiile mobile, începea cloud computingul, iar datele personale migrau rapid de pe calculatoarele noastre către servicii online. Problema era că acele servicii nu ofereau aproape nicio garanție: nu știai exact ce fac cu datele tale, cât timp le păstrează sau dacă le poți șterge cu adevărat. Nu exista GDPR, nu existau sistemele solide de permisiuni de pe mobile pe care le avem azi, nu existau barierele legale legate de vânzarea datelor personale. Practic, tehnologia evoluase mai repede decât protecția utilizatorilor. Practic, teza mea a pornit din ideea că pierderea controlului asupra datelor devenise o problemă reală și nouă. M-am întrebat dacă utilizatorul poate recâștiga măcar o parte din control, chiar și atunci când serviciile online nu sunt cooperante. Ce am propus, pe scurt, au fost mecanisme tehnice – în mare parte bazate pe criptare – prin care utilizatorul să își poată impune propriile reguli. De exemplu, un sistem prin care datele se „autodistrug“ prin distrugerea cheii de criptare, sau un sistem de audit în care accesarea neautorizată declanșa un fel de „alarmă“ criptografică. Nu era vorba doar de recuperarea datelor după un atac, ci de a schimba raportul de putere: chiar dacă îți pui datele în cloud, să nu le pierzi complet controlul.
Între academis și colaborarea cu giganții tech
Ați colaborat cu Google, Meta și Microsoft și încă o mai faceți. Cum împăcați libertatea academică de a critica industria cu colaborările cu marile companii tech?
E o întrebare foarte importantă. Când studiam Gmail cu XRay, aveam în paralel un proiect complet separat finanțat de Google – un sistem distribuit de publish-subscribe, fără nicio legătură cu cercetarea mea în confidențialitate. Proiectele erau distincte, cu obiective și echipe de studenti diferite. Faptul că existau colaborări industriale nu a influențat ce investigam în mod independent. Acum, în anul meu sabatic de la Columbia, continui proiectele academice de la Columbia – unele în colaborare cu Meta și Mozilla pe standardul Attribution – iar în paralel lucrez la Google pe securitatea agenților AI. Ca profesor, este normal să ai finanțări din surse diverse și parteneriate cu industria. De fapt, interacțiunea cu parteneri industriali este esențială dacă vrei să ai impact real. Important este să separi clar proiectele și să îți folosești constant busola etică și procesele științifice riguroase, astfel încât parteneriatele să nu influențeze concluziile la care ajungi. Realist vorbind, nimeni nu este complet imun la biasuri. Tocmai de aceea transparența este esențială. Declar toate colaborările și potențialele conflicte de interese, astfel încât ceilalți – fie partenerii industriali, fie colegi din comunitatea științifică, fie publicul larg – să poată evalua singuri contextul în care vin propunerile sau concluziile mele. Pentru mine, cheia este această combinație: separare clară a proiectelor, rigoare profesională și transparență totală.
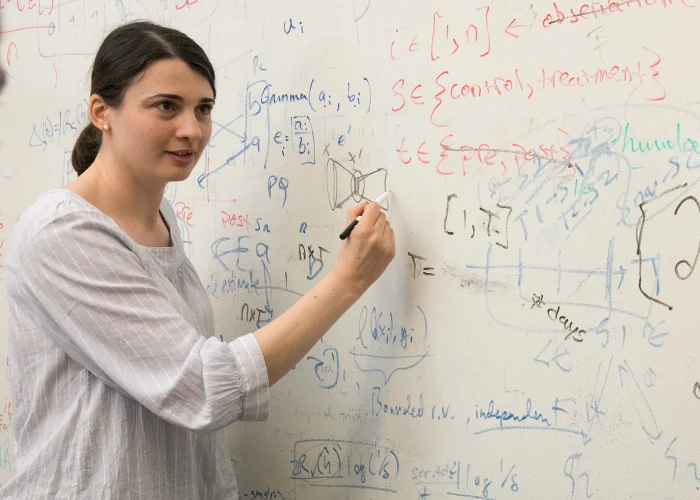
Roxana Geambașu la curs în fața studenților
Ați fost inclusă de „Popular Science“ în topul celor mai străluciți 10 cercetători. Pun astfel de premii o presiune suplimentară asupra direcției cercetării?
Nu mi-am ales sau influentat niciodată direcțiile de cercetare în funcție de premii sau granturi. Întotdeauna am pornit de la ce cred eu cu adevărat, de la problemele care mi se par importante sau deranjante, și abia apoi am aplicat pentru finanțări sau alte forme de recunoaștere, explicând ce vreau să fac. În cazul premiului de la „Popular Science“, nici măcar nu îmi amintesc să fi aplicat – cred că funcționează prin nominalizări făcute de alții. A fost o surpriză plăcută, dar nu ceva care să îmi fi schimbat direcția. Dacă cineva decide să finanțeze ideile la care lucrez, e foarte bine. Dacă nu, caut alte surse. Dar nu pornesc niciodată invers, adică de la „ce ar da bine“ sau „ce ar fi premiabil“. Direcția vine din convingere, nu din strategie.
Viața dincolo de internet
Viața de profesor la Columbia și cercetător de top este extrem de solicitantă. Ce face Roxana Geambașu atunci când închide laptopul și cum aduce echilibrul în viața privată? Aveți vreo pasiune care nu are nicio legătură cu algoritmii?
Îmi place foarte mult să petrec timp cu familia și să mă joc cu fetița mea de 9 ani. Asta este, de departe, cea mai importantă formă de echilibru pentru mine. În rest, alerg și încerc să petrec cât mai mult timp în natură. Poate pare surprinzător, pentru că New Yorkul e perceput ca o aglomerare de beton și sticlă, dar în afara zonelor foarte turistice este surprinzător de verde. Locuiesc pe Upper West Side, în Manhattan, și sunt înconjurată de parcuri: la est e Central Park, la vest Riverside Park, de-a lungul râului Hudson, iar la nord sunt Morningside Park și campusul Columbiei – toate la câteva străzi distanță. Riverside Park face parte dintr-un sistem continuu de trasee care urcă sute de kilometri, până în Canada. În Manhattan, segmentul are cam 20 de kilometri de la sud la nord. Când e vreme bună, îmi rezerv ore întregi și alerg zeci de kilometri. Vara, dacă trebuie să ajung undeva în Manhattan, nu iau metroul și nici mașina – nici nu am permis – ci merg pe jos sau alerg. Îmi place să spun, în glumă, că folosesc parcurile ca pe autostrăzi: intru pe „traseu“, avansez, schimb dintr-un parc în altul și la destinație ies de pe „autostradă“. Îmi place mult să explorez orașul și să descopăr detalii arhitecturale sau inginerești care, la prima vedere, sunt invizibile. New Yorkul e extrem de complex, iar aglomerația lui forțează soluții ingenioase. De exemplu, unde locuiam înainte, aveam vedere la Hudson. Între clădirea noastră și râu erau „împachetate“ o autostradă, o rampă de ieșire, o pistă de biciclete, parcul pe mai multe niveluri și o cale ferată îngropată. Dacă nu știai că sunt acolo, nici nu le observai. Un alt exemplu fascinant este Bryant Park, în spatele Bibliotecii Centrale din New York. La suprafață vezi copaci, bănci și gazon. Dedesubt însă se află un depozit imens de cărți, cu rafturi peste rafturi, de unde volumele sunt trimise în sălile de lectură printr-un sistem de trenulețe. Cărțile sunt ținute acolo pentru că în clădirea istorică sunt mai greu de controlat temperatura și umiditatea. Dacă ești în parc, nu ai nici cea mai mică idee că alergi deasupra unui „buncăr“ plin de cărți, unele vechi și unicat. Singurul indiciu este într-un colț discret al parcului, unde se află o placă memorială. Dacă te uiți atent, îți dai seama că este, de fapt, formată din ușile unei ieșiri de urgență din depozitul subteran. Genul acesta de descoperiri mă pasionează. Îmi place să citesc despre ele, să le investighez și să înțeleg cum funcționează lucrurile dincolo de suprafață. Cred că e o extensie naturală a felului în care gândesc și în cercetare – doar că aici o fac fără laptop.
Sunteți un model pentru multe tinere care vor să urmeze Computer Science. Care credeți că este încă cea mai mare barieră pentru femeile din cercetarea de vârf în informatică?
Cred că cea mai grea barieră este, în continuare, încrederea în sine. Văd asta la studenții mei: unii sunt foarte încrezători, alții se îndoiesc constant de propriile capacități. Există oameni de toate genurile în ambele categorii, dar, din experiența mea, femeile tind mai des să fie mai timorate și mai nesigure. Iar asta contează mult. În cercetare – și, de fapt, în orice carieră ambițioasă – trebuie să îți asumi riscuri. Să accepți o poziție mai incertă. Să mergi înainte cu o idee care nu e încă validată. Să convingi alți oameni să ți se alăture. Fără un minim de încredere în tine, e foarte greu să faci aceste lucruri. Eu am avut mare noroc să am mentori foarte buni – nu doar coordonatorii de doctorat, ci profesori încă din școala generală – care m-au încurajat și au investit timp și energie în mine. Când începi să vezi rezultate și simți că cineva are încredere în tine, prinde contur și încrederea proprie. Sfatul meu pentru cei care vor să intre în domeniu, dar nu sunt siguri că sunt în stare, este: 1. să țină cont că aproape toți trecem prin această îndoială la început; 2. să încerce chiar dacă nu sunt convinși că vor reuși – și chiar dacă primele încercări nu ies; 3. dacă pot, să caute oameni bine intenționați și competenți care să le ofere feedback și sprijin. Nu e ușor, și uneori ține și de noroc să întâlnești persoanele potrivite. Dar, din experiența mea, mulți oameni sunt dispuși să ajute când văd pe cineva serios și muncitor, cel puțin până la un punct – uneori acel punct este suficient. Eu am avut această șansă în România și apoi în SUA, iar asta a contat enorm.
Cine ar fi capabil să preia din responsabilitățile SUA, dacă americanii se retrag din NATO. „E în măsură să garanteze securitatea României”
„Munca, inițiativa și perseverența cântăresc mai mult decât numele universității“
Ce le-ați spune studenților de la Politehnică din România care se tem că nu pot concura cu cei de la Stanford, Columbia, Harvard, Yale sau MIT?
În primul rând, să nu se compare obsesiv cu alții. Mai important decât unde înveți este cât de serios înveți. Munca, inițiativa și perseverența cântăresc mai mult decât numele universității. Am avut colegi în liceu și în facultate în România care ar putea concura oricând cu cei mai buni oameni pe care îi cunosc de la MIT, Stanford, Berkeley sau Columbia. Talente există peste tot. Diferența reală o face cât ești dispus să muncești și cât de consecvent ești. Știți vorba aia, atribuită lui Thomas Edison: succesul vine 90% din perseverenţă și doar 10% din inspirație. Eu sunt convinsă că în lume există mulți oameni cu mult mai buni decât mine. Dar cred și că, dacă depun efort și sunt consecventă, este loc și pentru mine să am impact. Iar în nișa mea – arhitectura de confidențialitate pentru date la scară mare – eu cred că sunt printre cercetătorii de top din lume și că sunt recunoscută ca atare de comunitate. Nu pentru că am fost la o anumită universitate, ci pentru că am muncit mult și am fost perseverentă – și, într-adevăr, am avut și noroc de mentori buni. E adevărat că există o diferență de șanse. Studenții de la universități foarte renumite au adesea acces mai ușor la internshipuri sau la anumite cursuri speciale. Dar există oportunități bune și în România – poate mai multe decât acum 25 de ani. Diferența majoră o fac lucruri pe care studentul le poate controla: cât muncește, câtă inițiativă are, cât de mult insistă când lucrurile nu ies. Studenții buni și muncitori pot ajunge foarte departe.
Dacă un tânăr v-ar întreba în ce direcție merită să se specializeze în următorii ani, ce i-ați răspunde?
E foarte greu de prezis acum. Suntem în mijlocul unui uragan tehnologic numit AI, ale cărui limite încă nu le înțelegem. Vedem deja lucruri care, acum câțiva ani, păreau extrem de greu de automatizat și rezervate celor mai buni ingineri. De exemplu, un cercetător de la Anthropic a povestit cum o echipă de agenți AI pe care o superviza a reușit să genereze un compilator C care, în final, a putut compila kernelul (n.r. – nucleul sistemului de operare) Linux. Pe vremea când eram eu studentă, compilatoarele erau considerate printre cele mai dificile sisteme de construit. Faptul că agenți AI pot produce astfel de componente este, sincer, uimitor. Nu înseamnă că orice sistem complex va fi ușor de automatizat. Compilatoarele și limbajul C sunt bine definite și au teste clare, iar AI-ul poate învăța din multe implementări existente. Dar e posibil ca lucrurile pe care le credeam cele mai grele – detaliile tehnice fine – să fie exact cele pe care mașinile le pot face cel mai bine. Iar limitele reale încă nu le știm. De aceea nu cred că e o strategie bună să optimizezi cariera pe baza unei „nișe future-proof“. Pur și simplu nu avem suficiente informații ca să prezicem ce va rămâne stabil. Sau cel puțin, eu nu am suficiente informații. În schimb, i-aș încuraja pe tineri să se pregătească pentru adaptare continuă. Să învețe foarte bine bazele, inclusiv interdisciplinar. Cei din zona Real să nu ignore materiile umaniste, iar cei din zona Uman să nu fugă de matematică și științe exacte. Fundamentele diverse de gândire cred că vor conta enorm. Cred că există oportunități mari la intersecția dintre științele exacte și domenii precum filozofia, etica, psihologia sau sociologia. Astăzi, când programăm agenți AI, le dăm instrucțiuni care seamănă uneori mai mult cu îndrumările unui profesor către un student decât cu programarea clasică în cod. Discutăm despre reguli, responsabilitate, limite, chiar despre cum ar putea arăta o societate de agenți, cu legi și repercusiuni. Sunt conversații care, acum câțiva ani, mi s-ar fi părut mai degrabă filozofice decât inginerești, iar acum le am cu colegii mei ingineri. Pentru mine a funcționat specializarea profundă într-o nișă. Nu sunt convinsă că aceeași strategie va funcționa pentru generația care vine. Eu însămi încep acum să colaborez explicit cu filozofi, tocmai pentru a completa golurile lăsate de hiper-specializare. Sfatul meu ar fi: construiți baze solide, rămâneți flexibili, urmați ce vă pasionează și fiți pregătiți să vă reinventați de mai multe ori. Timpurile sunt interesante. Mai bine ne ținem ochii larg deschiși și învățăm constant, decât să căutăm o nișă care pare sigură astăzi și s-ar putea să nu mai fie mâine.

Roxana Geambașu în 2011
Trei motive de optimism
Care sunt, în opinia dumneavoastră, trei riscuri majore ale AI și trei motive de optimism?
Sunt multe lucruri care mă îngrijorează legat de evoluția AI, dar dacă ar fi să aleg trei:
1. Dezinformarea sistemică amplificată de AI. Capacitatea de a genera conținut credibil, la scară masivă, poate destabiliza spațiul informațional. Nu mai vorbim doar de știri false izolate, poate amplificate algoritmic în anumite grupuri sau rețele sociale, ci de ecosisteme întregi de conținut generat automat.
2. Riscul unor situații catastrofice prin agenți AI conectați la sisteme reale critice omenirii. Pe măsură ce agenții primesc acces la infrastructuri digitale, pot apărea scenarii grave: atacuri asupra utilităților, blocaje ale unor sisteme critice, pierderea conectivității în zone mari. Nu spun că e inevitabil, dar suprafața de risc crește.
3. Capacitatea societății de a se adapta la schimbări rapide în piața muncii. În special în domeniile administrate digital, transformările pot fi bruște. Eu cred că roboții fizici sunt încă relativ departe, dar munca intelectuală procedurală este deja afectată. Întrebarea reală este cât de repede pot sistemele educaționale și economice să țină pasul. La Columbia, de exemplu, ne întâlnim frecvent să discutăm cum trebuie să ne schimbăm curriculumul. Unii dintre noi, inclusiv eu, mergem în industrie tocmai pentru a înțelege mai bine ce se schimbă și ce tipuri de competențe vor fi căutate, ca să știm cum să adaptăm programele de studiu. Sper sincer că astfel de reflecții au loc peste tot. Instituțiile educaționale, nu doar tinerii înșiși, au responsabilitatea să se adapteze. Cei care ies acum de pe băncile școlii sunt cei de nivel „entry-level“, care întâmpină o piață a muncii mult mai instabilă decât acum câțiva ani. Nu îi putem lăsa singuri să se descurce. Programele trebuie actualizate, iar în paralel trebuie create mecanisme serioase de re-calificare și adaptare pentru populația activă. Vor fi probabil necesare și alte schimbări în societate, dar eu mă rezum la educație, pentru că este domeniul pe care îl înțeleg cel mai bine.
Ce ar trebui să ne facă optimiști?
În primul rând, coborârea barierei pentru a construi lucruri noi. Astăzi, doi oameni cu o idee bună și o echipă de agenți AI pot lansa un produs fără investiții uriașe în echipe tehnice sau suport. Asta poate democratiza inovația. Apoi, creșterea utilității reale a calculatoarelor. Pentru prima dată, interacțiunea cu tehnologia devine naturală. Calculatoarele pot deveni mai accesibile pentru oameni care nu sunt tehnici, ceea ce e un salt enorm. Și, nu în ultimul rând, progrese în domenii precum medicina. În cercetarea biomedicală, multe probleme țin de identificarea de patternuri complexe în date. Exact la asta AI este foarte bun. Există șansa reală să vedem descoperiri accelerate în tratamente sau diagnostic. Per total, AI nu este nici doar amenințare, nici doar salvare. Este o tehnologie extrem de puternică. Direcția în care va merge depinde foarte mult de cum o proiectăm, cum o reglementăm și cum alegem să o folosim.
În doctorat ați studiat cum își pot recăpăta utilizatorii controlul asupra datelor lor. Care era problema pe care încercați să o rezolvați?
Perioada în care mi-am făcut doctoratul, a doua jumătate a anilor 2000, a fost un moment de schimbare tehnologică semnificativă. Webul se stabilizase, explodau rețelele sociale si aplicațiile mobile, începea cloud computingul, iar datele personale migrau rapid de pe calculatoarele noastre către servicii online. Problema era că acele servicii nu ofereau aproape nicio garanție: nu știai exact ce fac cu datele tale, cât timp le păstrează sau dacă le poți șterge cu adevărat. Nu exista GDPR, nu existau sistemele solide de permisiuni de pe mobile pe care le avem azi, nu existau barierele legale legate de vânzarea datelor personale. Practic, tehnologia evoluase mai repede decât protecția utilizatorilor. Practic, teza mea a pornit din ideea că pierderea controlului asupra datelor devenise o problemă reală și nouă. M-am întrebat dacă utilizatorul poate recâștiga măcar o parte din control, chiar și atunci când serviciile online nu sunt cooperante. Ce am propus, pe scurt, au fost mecanisme tehnice – în mare parte bazate pe criptare – prin care utilizatorul să își poată impune propriile reguli. De exemplu, un sistem prin care datele se „autodistrug“ prin distrugerea cheii de criptare, sau un sistem de audit în care accesarea neautorizată declanșa un fel de „alarmă“ criptografică. Nu era vorba doar de recuperarea datelor după un atac, ci de a schimba raportul de putere: chiar dacă îți pui datele în cloud, să nu le pierzi complet controlul.
Nu pot să nu vă întreb despre proiectul dumneavoastră Vanish, pe care l-ați condus personal în anii doctoratului și care a atras atenția întregii lumi. Cum se protejează datele conținute în orice formă de poșta electronică, utilizând așa-numitul algoritm al datelor autodistructive?
Vanish a pornit de la o observație simplă: pe internet, nimic nu moare cu adevărat. Odată ce ai trimis un e-mail sau ai încărcat un fișier, nu mai ai control real asupra lui. Poate fi copiat, arhivat, păstrat la nesfârșit. Ideea din spatele Vanish a fost să schimbăm asta folosind criptarea. În loc să încercăm să ștergem datele de peste tot – lucru aproape imposibil –, am protejat cheia care le permite să fie citite. Datele sunt criptate, iar cheia de decriptare este împărțită în bucăți și răspândită într-o rețea distribuită de calculatoare. În timp, acele bucăți dispar natural din rețea, iar când dispar suficient de multe, cheia nu mai poate fi reconstruită. Fără cheie, datele devin imposibil de citit. Așa funcționează „autodistrugerea“: nu ștergi neapărat fișierul, ci îl faci imposibil de descifrat după un anumit timp. Practic, mesajul expiră singur. Iar timpul de expirare se poate controla statistic prin fixarea unor parametri ai criptării. Astăzi există concepte precum „dreptul de a fi uitat“ din GDPR. Interesant este că unele implementări serioase ale cerințelor de ștergere a datelor personale folosesc aceeași idee de bază pe care am folosit-o în Vanish – idee care, la rândul ei, a fost inspirată dintr-un sistem anterior, numit Ephemerizer: criptarea datelor și distrugerea cheii. În sisteme mari și complexe, este adesea mult mai simplu și mai sigur să gestionezi și să distrugi cheia de criptare decât să te asiguri că fiecare copie a datelor a fost ștearsă fizic din toate colțurile infrastructurii.
Cât suntem în control asupra datelor proprii
Credeți că în prezent, cu evoluția tehnologiilor cloud, mai este posibil cu adevărat ca un utilizator să aibă control total asupra „termenului de valabilitate“ al datelor sale?
Poate părea surprinzător, dar dacă lăsăm la o parte momentul actual dominat de AI – care creează un nou val de schimbări –, situația controlului asupra datelor personale chiar s-a îmbunătățit în ultimul deceniu. Asta se datorează în mare parte unor legi relativ recente, precum GDPR în Uniunea Europeană sau CCPA/CPRA în California, dar și altor reglementări similare din SUA și restul lumii. Ele au impus reguli mai clare: ce date pot fi colectate, când e nevoie de consimțământ explicit, cât timp pot fi păstrate datele și ce drepturi are utilizatorul. În paralel, au apărut și standarde tehnice noi, cum ar fi Global Privacy Control al W3C, care permite exprimarea automată a preferințelor legate de vânzarea datelor, sau standardul W3C Attribution, la care am contribuit și eu prin dezvoltarea arhitecturii de confidențialitate. Toate acestea oferă alternative mai transparente și mai controlabile decât ce exista în anii 2005-2015. Comparativ cu perioada în care mi-am făcut doctoratul, lucrurile ajunseseră, până recent, să stea mult mai bine din perspectiva controlului și transparenței. Îmi place să cred că munca mea din anii 2005-2015, inclusiv proiecte precum Vanish sau XRay, a avut măcar un mic rol în dezbaterea publică și tehnică ce a contribuit la aceste schimbări. Proiecte mai recente, precum Cookie Monster și Big Bird, au fost integrate direct în standardul W3C Attribution pentru publicitate online cu protecția confidențialității, iar alte tehnologii dezvoltate de noi au fost adoptate de companii. Standardul Attribution este în prezent în proces de specificare și, dacă va fi adoptat, va rula în toate browserele majore – Chrome, Firefox și Safari –, adică va fi distribuit pe miliarde de dispozitive din întreaga lume. Sper că, în timp, acest lucru să ducă la o schimbare reală în bine a confidențialității online. Desigur, apariția AI complică din nou lucrurile. Suntem într-un nou moment de dezechilibru, în care regulile și mecanismele de control au dificultăți, încă o dată, să țină pasul cu tehnologia.
Summitul București 9. România cu imaginea, Polonia cu agenda. Expert: „Centrul de greutate și interesul e pe Baltica, nu pe Marea Neagr㔄Spaima“ giganților tech
Lucrați mult pe conceptul de Differential Privacy. Cum ați explica pe înțelesul unui student de anul I de ce această metodă este mai sigură decât simpla anonimizare a datelor?
Anonimizarea clasică înseamnă, de obicei, că scoți numele, CNP-ul sau alte identificatoare directe dintr-un set de date și speri că asta e suficient. Problema e că, de multe ori, nu este. Dacă cineva are informații suplimentare – de exemplu vârstă, cod poștal și sex – poate reidentifica persoane chiar și din date „anonimizate“. Istoria ne-a arătat de multe ori că anonimizarea simplă se poate sparge. Differential Privacy pornește de la o idee diferită. Nu promite că datele sunt anonime, ci oferă o garanție matematică: rezultatul unei analize nu se schimbă semnificativ dacă o persoană este sau nu în baza de date. Cu alte cuvinte, contribuția fiecărui individ este limitată în mod controlat. Pe scurt, anonimizarea încearcă să ascundă identitatea în datele brute. Differential Privacy limitează ce se poate afla despre orice individ din rezultate. De aceea e mai sigură: nu se bazează pe presupunerea că adversarul nu știe prea multe, ci oferă protecție chiar și atunci când știe foarte multe. Mai are și alte avantaje importante când construiești sisteme complexe. Dacă proiectezi componentele astfel încât fiecare să respecte Differential Privacy, ele se pot compune și sistemul, ca întreg, păstrează garanția de confidențialitate. Anonimizarea nu are această proprietate: două seturi „anonimizate“ combinate pot deveni brusc reidentificabile. Un exemplu clasic este cazul data-setului publicat de Netflix pentru un concurs de recomandare de filme. Deși datele nu conțineau nume, cercetătorii au arătat că unele persoane pot fi reidentificate prin corelarea evaluărilor de filme cu informații publice de pe IMDb. În plus, Differential Privacy îți spune clar care e relația dintre confidențialitate și acuratețe: câtă precizie pierzi pentru a proteja datele. Iar în general, cu cât ai mai multe date, cu atât poți obține rezultate mai precise, păstrând totuși garanția de protecție. Anonimizarea nu oferă astfel de garanții clare. Când construiești un sistem mare, care procesează multe date și vrei o promisiune reală de confidențialitate, Differential Privacy este practic singura abordare care îți dă o garanție formală pe care o poți înțelege și peste care poți continua să construiești.
Ați dezvoltat instrumente ca XRay pentru a vedea cum giganții tech ne folosesc datele pentru publicitate. Care a fost cea mai surprinzătoare descoperire pe care ați făcut-o monitorizând aceste fluxuri de date?
XRay a fost un sistem pe care l-am dezvoltat în perioada 2013-2015 pentru a înțelege, în mod riguros, cum folosesc platformele online datele noastre pentru publicitate și recomandări. Ideea era simplă, dar puternică: creai mai multe conturi controlate, în care modificai sistematic anumite informații – de exemplu, conținutul unor e-mailuri – și apoi măsurai cum se schimbă reclamele afișate. Prin analiză statistică, puteam identifica ce tip de informație declanșa ce tip de reclamă. Cea mai surprinzătoare descoperire a fost legată de Gmail. Google declarase public că nu folosește conținutul mesajelor pentru anumite tipuri de targetare publicitară sensibile, cum ar fi cele legate de sănătate, rasă sau situație financiară. Când am analizat datele cu XRay, am observat corelații între subiecte discutate în e-mailuri și reclame din astfel de categorii sensibile. De exemplu, mesaje care sugerau o problemă medicală gravă, precum cancerul, erau urmate de reclame pentru produse de medicină holistică sau servicii de tip șamanic. Nu afirmația în sine a fost șocantă, ci diferența dintre politica declarată și ceea ce am măsurat noi, riguros și științific, că se întâmpla în realitate. Gmail a oprit serviciul de publicitate pe care îl studiam în timp ce noi continuam să colectăm date, dar după ce ne-am publicat rezultatele. Pentru mine, lecția a fost că transparența nu poate exista doar la nivel de politică declarat. În sisteme atât de complexe, e nevoie de instrumente care să verifice cum funcționează lucrurile în practică, nu doar cum ar trebui să funcționeze în principiu. La scurt timp după aceea, marile platforme de publicitate au început să introducă explicații de tip „De ce văd reclama asta?“, oferind utilizatorilor mai multă vizibilitate direct din interiorul sistemului. A fost un pas important spre transparență, chiar dacă nu rezolvă toate problemele.

„Spamul și tentativele de fraudă au devenit mult mai sofisticate“
În contextul exploziei modelelor de limbaj (LLM), cât de real este riscul ca datele noastre private să ajungă în memoria modelelor AI?
AI-ul, inclusiv LLM-urile, și mai ales agenții AI care rulează peste ele și au acces la unelte cu care pot acționa în lumea digitală, reprezintă o nouă provocare majoră, atât pentru confidențialitatea datelor, cât și pentru securitatea cibernetică și multe alte aspecte ale societății. Personal, nu am început încă să lucrez direct pe partea de confidențialitate pentru LLM-uri, pentru că mi se pare că, în momentul acesta, securitatea cibernetică e chiar mai importantă. Sunt în anul sabatic de la Columbia și m-am hotărât să merg la Google ca să lucrez la o arhitectură de siguranță pentru agenți AI. Am o idee și vreau să o testez în practică. Legat strict de întrebarea despre memoria permanentă: riscul există, dar cred că încă învățăm cum sunt folosite datele în astfel de sisteme și unde apar exact scurgerile reale. Pentru confidențialitate, cred că va trebui să mai așteptăm puțin ca să înțelegem mai bine niște șabloane și structuri ale folosirii datelor. Abia după aceea putem să introducem bariere care chiar funcționează. Problema e că soluțiile de confidențialitate cer, aproape întotdeauna, niște limite pe funcționalitate. Iar acum, agenții AI sunt imaginați ca sisteme care pot face orice. În acest context, e greu să pui bariere fără să tai utilitate, reală sau percepută. Sper însă că, pe măsură ce domeniul se maturizează, o să vedem șabloane mai stabile și structuri mai clare, iar atunci o să putem introduce protecții de confidențialitate care nu distrug, în același timp, utilitatea acestor agenți.
Protecția pe internet
Într-un interviu menționați că vă alegeți proiectele în funcție de ce vă „enervează“ la tehnologia actuală. Ce vi se pare cel mai problematic la modul în care funcționează internetul astăzi?
Dacă lăsăm agenții AI la o parte – pentru că sunt încă prea noi ca să avem soluții stabile –, ce mă enervează cel mai tare la web și la mobile în 2026 este lipsa unei separări clare între funcționalitățile primare și cele secundare. Funcționalitățile primare sunt motivele pentru care folosești un site sau o aplicație: să vezi un film, să citești știri, să vorbești cu prietenii. Funcționalitățile secundare sunt publicitatea, recomandările și alte mecanisme de monetizare. Nu cred că e ceva fundamental greșit cu niciuna dintre ele. Problema este că sunt amestecate. De multe ori, nu funcționalitățile primare generează munții de date colectate în backend, ci cele secundare. Publicitatea, de exemplu, a dus la cross-site tracking masiv, nu faptul că vrei să citești un articol sau să trimiți un mesaj. Cred că, dacă am separa mai clar aceste funcționalități, am putea construi mecanisme de confidențialitate mai curate și mai transparente.
Care sunt cele mai mari riscuri pentru un utilizator obișnuit de internet astăzi?
E o întrebare grea, pentru că lista e lungă. Dar dacă ar fi să simplific, cred că în acest moment cele mai mari pericole pentru utilizatorul obișnuit sunt legate de scamuri și dezinformare, amplificate de AI. Spamul și tentativele de fraudă au devenit mult mai sofisticate. Mesajele sunt mai bine scrise, mai personalizate și mai convingătoare. AI-ul le face „turbo-charged“. E mult mai greu să îți dai seama dacă un e-mail sau un mesaj este real sau o tentativă de fraudă. Un alt risc este instalarea sau conectarea unor agenți AI care au acces la conturile și serviciile tale fără să înțelegi exact ce permisiuni le dai. În momentul în care un astfel de sistem are acces la e-mail, documente sau alte servicii, riscul crește considerabil. Mai e și problema încrederii necritice în ceea ce spun chatboții AI. Ei pot greși, pot „inventa“ informații sau pot genera conținut convingător, dar fals. Iar pe rețelele sociale, unde dezinformarea era deja o problemă, AI-ul poate amplifica fenomenul. Și un sfat foarte practic: țineți-vă sistemele actualizate. Cu AI la îndemâna oricui, vulnerabilitățile pot fi descoperite mult mai rapid. Probabil și patch-urile vor apărea mai repede, dar doar dacă le instalați. Amânarea update-urilor este una dintre cele mai simple și mai periculoase greșeli.
Sursa: adevarul.ro